
Working with 5G and mmWave applications presents a new set of challenges that are quite different from what we’re used to when planning and deploying wireless networks. As these high-frequency applications are extremely line-of-sight dependent, even minor foliage and obstructions can degrade or block a signal. Add the fact that networks are being deployed in challenging service areas that include buildings, trees and other obstructions, and the need for highly detailed data when planning these networks becomes crucial.
When working on 5G networks, a traditional database will not provide the accuracy or level of detail needed when trying to address these challenges. At best, these traditional databases will require manual manipulations in an attempt to make them as accurate as possible. But of course manual manipulations can only do so much and, more importantly, this comes at the expense of wasting engineering time and real-world dollars.
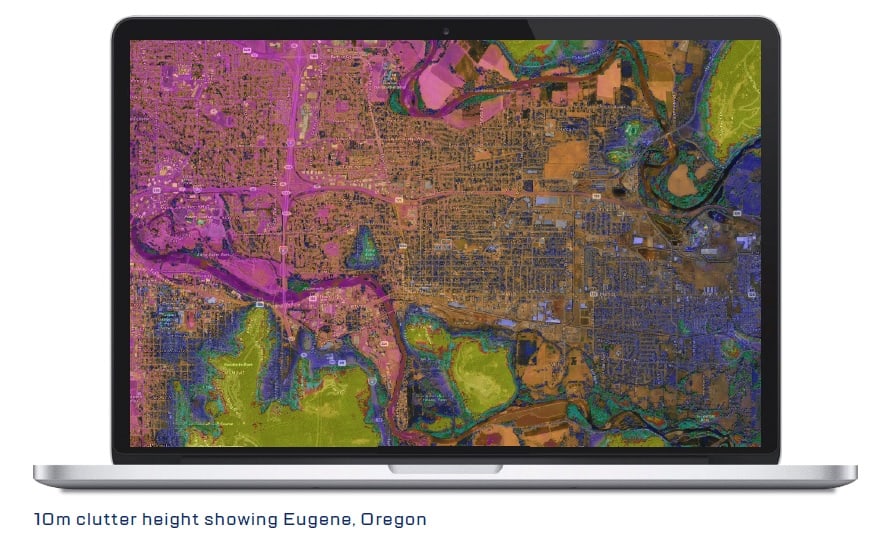
As the world moves more toward 5G, mmWave and Smart City deployments, the use of clutter height data has become an imperative part of our work.
What is clutter height data?
As the name suggests, clutter height data assigns a height value for clutter. What sets it apart from traditional clutter databases is that it assigns an individual height per bin, rather than a blanket height covering an entire clutter category.
The result is an extremely detailed and accurate model of the service area that takes into account vegetation and man-made features on a per bin basis: the type of accuracy needed for 5G and mmWave network planning and deployments.
Clutter height data depicts all potential obstructions with the height for each, even in mixed service area environments such as this area of Chicago which includes commercial, residential, golf course, transportation corridors and water.
Don’t traditional clutter data attenuation files have a height value associated to it?
Yes, but the attenuation values found in a traditional clutter database provide only an average height that is assigned to the entire clutter category. It is a blanket value that gets applied across an entire region, which would be the particular clutter category
For example, if you were working in a service area which had a region defined as “developed high intensity” and a corresponding attenuation file that assigned a height value of “5m” for that category, then everything that fell within that category would have the same height value.
Obviously in the real world, the structures, buildings and such that are present will not be a uniform height. This is precisely what clutter height databases address. Because rather than a uniform, average height assigned across an entire clutter category, an accurate, individual height is assigned per bin.

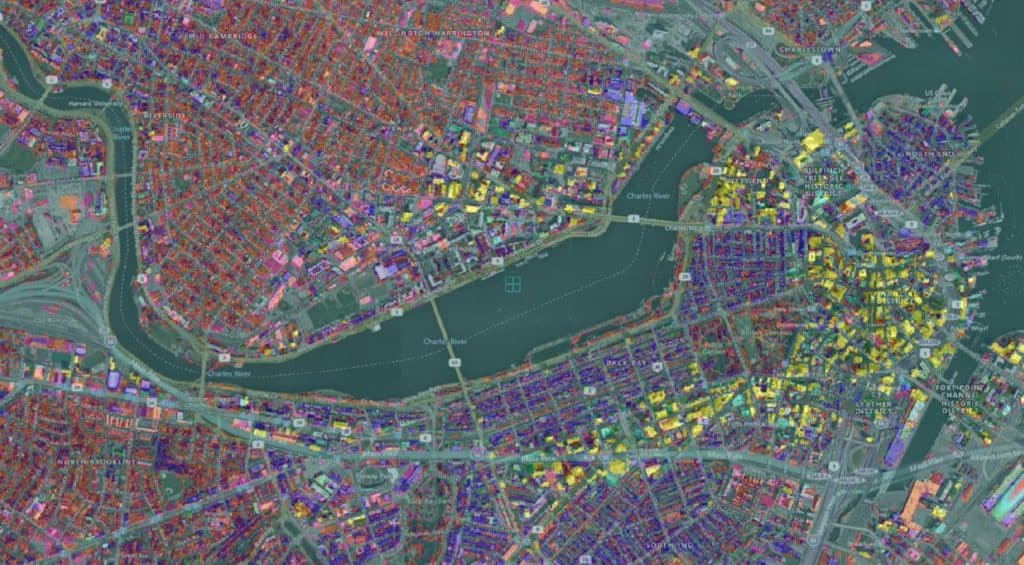
Clutter height data and the real world…
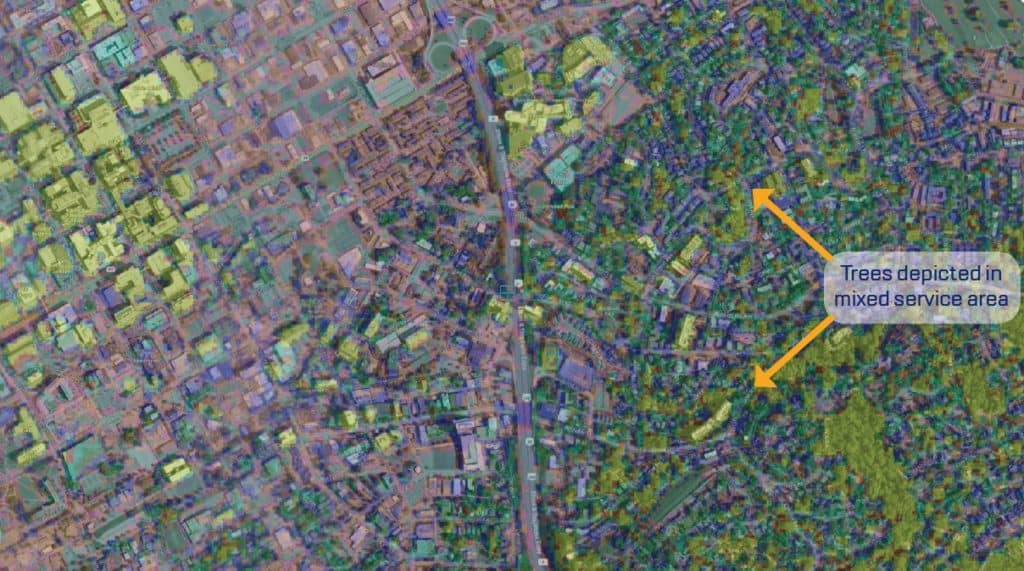
Clutter height offers a significant benefit over traditional clutter databases in that vegetation and trees are often depicted.
Given what we now know about the average heights applied across clutter categories in traditional clutter databases, it is obvious that these databases are not detailed enough to capture vegetation and trees. It will indeed be a major disappointment for network deployments with designs based strictly on a coarse resolution depiction of man-made features with uniform, average heights only to be deployed and affected by vegetation that were not taken into account in the initial design.
In this scenario, the additional hardware needed to make up for such design flaws can put a project significantly over budget, not to mention the serious potential performance issues.
Get the data to fit your needs
Flexible purchasing options allow you to procure the entire US, particular states, individual service areas or transportation corridors on a per-project basis.
Contact us to get data for your project or discuss with us to get recommendations.